
Research at the Speech Communication Lab focuses on combining the principles of science with the innovation of engineering to solve problems in speech and related areas. The emphasis of research is on understanding the principles of speech production and perception, and applying these principles in the development of acoustic parameters that will enable machines to automatically identify speakers or recognize speech. Research is also aimed at enhancing the quality of speech for such applications. All the projects are headed by Dr. Carol Espy-Wilson, the director of the Speech Communication Lab.
Speech Segregation
In this project, we focus on the problem of separating the speech of speakers talking simultaneously in a single-channel speech mixture. Shown below is an example where segregation was done using digital signal processing techniques. Currently we are exploring to enhance this task using deep learning.
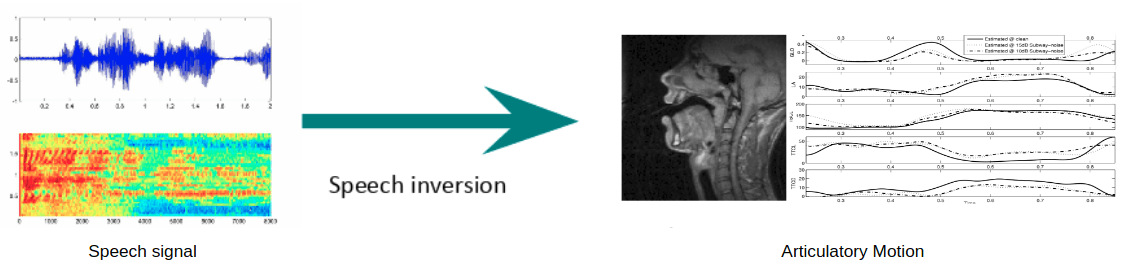
Speech Inversion
In this project, we have developed a mapping from acoustic features to articulatory parameter (vocal tract variables – TVs). We have shown that these the TVs added to the acoustic features MFCCs as input to an ASR system will make the system robust to noise. We are now exploring the use of these features to detect psychomotor retardation in people with major depression. In addition, we are developing assistive technologies to help (1)people with Residual Speech Sound Disorder, (2) people who want to reduce their accents or (3) people who want to learn how to produce sounds not in their native language. Finally, we plan to use the TVs in the warping of acoustic parameters for improved automatic recognition of speech spoken by people with foreign accents.
Emotion Recognition
Speech emotion recognition involves extracting meaningful features from a speech waveform and feeding them to a classifier to detect the emotional state of the speaker. We have compared different regularization schemes for neural network based classifiers and have shown that accounting for adversarial examples while training can help improve the performance of the model. Learning the underlying distribution of these feature vectors can be the key to understanding such emotion recognition models and towards that end we are comparing several GAN and variational autoencoder based generative models with more traditional models like GMM. Lastly we are also incorporating sentiment analysis from text into our models for multi-view learning. Currently we are working on developing a model to triage call center conversations.
Sentiment Analysis
With projects that require understanding the human emotion and intent from speech, only processing speech signal is not sufficient. We need to understand the language and words used by the users to make sense out of it , and to support the context for arousal and valence values extracted from speech signal. In this project, we focus on understanding the text part transcribed from the speech. We use simple dictionary approach (bag of words) to initially label the experience for speaker as positive, negative or neutral. Further, we plan to investigate more about the conversation structure and question-answering experience for agent and users.